
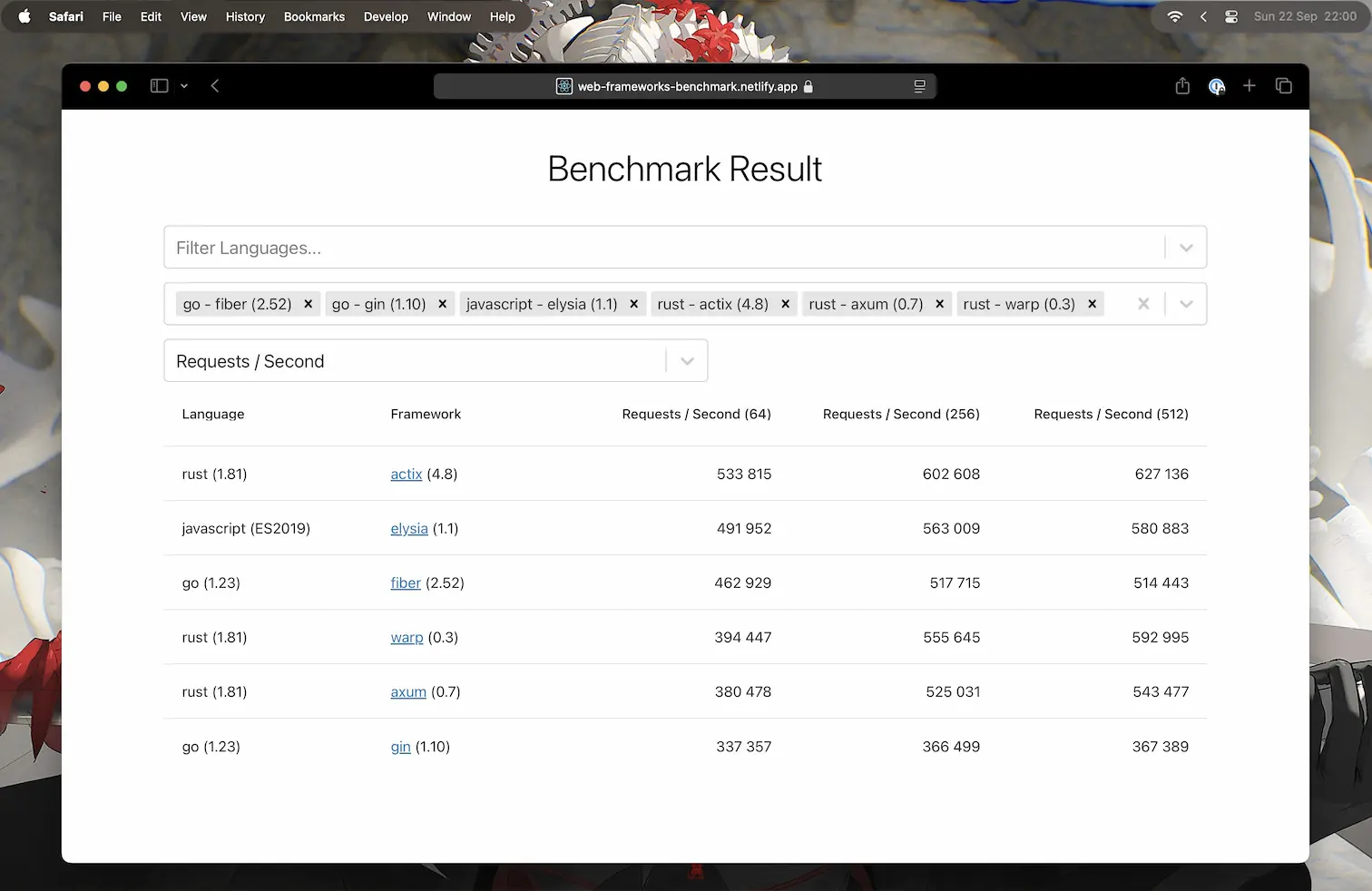
Elysia is fast.
There is no doubt about that.
In any benchmark, most of the time Elysia somehow outperforms other (JavaScript) frameworks in the same environment.
People jokingly says it is like a black magic.
But the behind the magic lies some interesting technology.
I mentioned Sucrose a lot in Elysia release note.
A fancy explaination with buzz words would be something like Static Code Analysis and Dynamic Code Injection using JIT compilation.
But I am not a fan of buzz words.
So let me explain it in a simple way.
Eval
We know that we can turn a string into a code using eval or new Function.
eval('console.log("Hello, World!")')
const say = new Function('something', 'console.log(something)')
say('Elysia daisuki') // Elysia daisukiWe often heard this practice is evil and should be avoided at all cost.
However, it is not entirely true.
People usually avoid eval because it can execute any code, including malicious code.
It is like giving a gun to a child.
It is dangerous.
It is easy to shoot yourself in the foot.
But it is not the gun itself that could endanger others, it is one who is wielding it.
If it is used properly, it can become a very powerful tool.
The reason why people dislike eval is because it is often used in a way that is not safe.
However, if we are entirely in the control of all input and handle it very carefully, it gives us a lot of power.
Library like ajv, typebox use eval to create dynamic validation code. They take the input, insert only the necessary code, and then execute it. Removing any unnecessary code thus nearly overhead.
Regardless of configurations or features they might have, it will almost nearly have no overhead if it is not in used.
Elysia also use eval in a similar way.
HTTP Handler
Take a look at this Elysia code
import { Elysia } from 'elysia'
new Elysia()
.post('/', (context) => 'Hello World')
.listen(3000)Each HTTP request parse a lot of features like body, query, header, etc.
Take a moment and think about how are you going to implement this?
Most people are going to create a centrailize function that parse the request and then pass it to the handler like this:
function centralFunction(request) {
const context = {
request,
body: await parseBody(request),
query: parseQuery(request.url),
headers: parseHeader(request.headers),
// and other stuff
}
const handle = router.find(request.method, request.url)
return mapResponse(handle(context))
}This is a good approach.
However, you can see that our user handler does not actually use any of the context.
import { Elysia } from 'elysia'
new Elysia()
.post('/', (context) => 'Hello World')
.listen(3000)This means that, parsing the request is unnecessary if the handler does not use it.
We can improve this a little bit by using a getter function.
function centralFunction(request) {
const context = {
request,
get body() {
// This is async
return parseBody(request)
},
get query() {
return parseQuery(request.url)
},
get headers() {
return parseHeader(request.headers)
},
// and other stuff
}
const handle = router.find(request.method, request.url)
return mapResponse(handle(context))
}However, if the property is async user need to use await it before using it.
import { Elysia } from 'elysia'
new Elysia()
.post('/', ({ body }) => {
body = await body
console.log(body)
return body
})
.listen(3000)This is a bit annoying.
From our perspective, we can clearly see that the handler only use body but code does not know.
Invisible Input
Talking about input, most of the time people think about passing parameter to a function.
But we can take a function itself as an input.
This might come with a bit of surprise, but you can also turn a code into a string as well.
function handler({ body }) {
body = await body
console.log(body)
return body
}
console.log(say.toString()) // function handler({ body }) { ... }Did you catch that?
We know that the handler function use a body and now we can programmatically extract it from the function. And with toString() we can somehow get the code in a string form.
If we could somehow have a parser that could read the parameters that user need…
That is exactly what Sucrose is.
Elysia can read your code
Sucrose is a nick name for a code parser.
It is a pattern-matching using partial AST parser that extract the necessary information from the handler function.
This is known as Static Code Analysis.
sucrose({
handler,
...lifeCycle,
}) // { body: true }Sucrose takes a function, and other life cycle function, and determine what might be used in the handler function.
Since Elysia handler take a function with exactly one parameter, we can view it as a DSL on top of JavaScript that user are not aware of.
Since we control the DSL, we can just narrow down the spec of JavaScript to a very small subset of feature that we are going to use.
And that is what Sucrose does.
Sucrose tells us which property is need for the handler function.
Putting it together
From the information we get from Sucrose, we can use eval to conditionally create a context based on what user need.
const inference = sucrose({
handler,
...lifeCycle,
})
let fn = 'const context = {'
if(inference.body)
fn += 'body: await parseBody(body)\n'
fn += '}'
fn += `return handler(context)`
return new Function('context', fn)This is a very simple example of how it works.
There are a lot of other things that we need to consider like error handling, async function, etc. But the idea is the same.
Compile time optimization
If you wrote C before, you might know that if you have a fixed size array and perform a loop, the compiler will optimize it by not using the array, but call the function directly instead.
int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for(int i = 0; i < 10; i++) {
printf("%d\n", arr[i]);
}The compiler will turn the code into:
printf("1\n");
printf("2\n");
// ... n time
printf("10\n");Becauase even though the array is fixed, the compiler can determine the value of the array at compile time.
In JavaScript, iterator also has (a tiny bit of) overhead, but if we know the value at compile time, we remove that overhead.
const lifecycle = {
beforeHandle: [someFn, someOtherFn],
afterHandle: []
}If we know that beforeHandler is always going to be empty, we can optimize it by not calling it at all.
// From
if(lifecycle.beforeHandle.length)
for(const fn of lifecycle.beforeHandle)
fn(context)
if(lifecycle.afterHandle.length)
for(const fn of lifecycle.afterHandle)
fn(context)
// To
lifeCycle.beforeHandler[0](context)
lifeCycle.beforeHandler[1](context)It is a very small optimization, but it is a small optimization like this that people often overlook.
An accumulation of small optimization can lead to a big performance gain.
These are kind of optimization that a compiler can does, and what Sucrose does is a very simple version of that.
Tracing
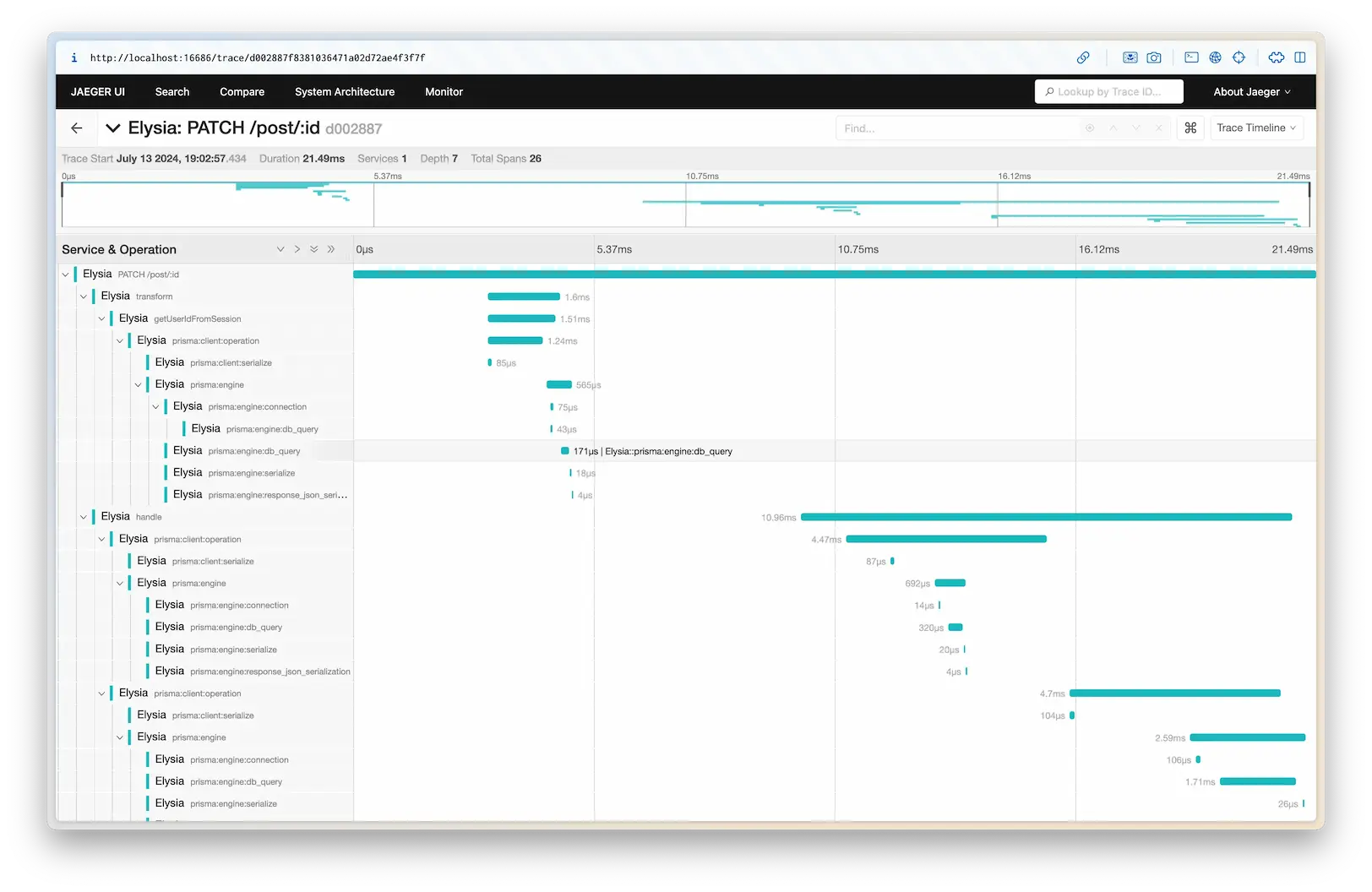
Elysia also provide a tracing feature that allow you to see what is going on in your application.
This is only possible through the use eval
Between each line/lifecycle, we can insert a tracing function that log what is going on, and measure the time it takes to execute.
This is a very powerful tool to see what is going on in your application, and this leads to better understanding of your application and how to optimize it.
This is how Elysia provide a support for an accurate OpenTelemetry out of the box without any overhead if you do not use it (which is likely impossible for others).
The drawback
eval is a very powerful tool, and with great power comes great responsibility. If you are not careful, you can easily shoot yourself in the foot.
I usually says that eval is a trade off between performance and maintainability. It is significantly harder to debug, and maintain as a maintainer.
ajv has been using eval for a long time, and it is one of the fastest schema validator out there and the industry relies on it. Elysia also does the same, but just in a bigger scale.
The only tradeoff for end user is a slight increase in bundle size, and slightly slower startup time but the performance gain is significant.
It is a trade off, but it is a trade off that we are willing to take.
Since Elysia handler can be optimized at compile time, it is significantly faster than other framework.
The compile time in this case is also a Just In Time Compilation (JIT) as it only compile the code that is going to be used when the handler is called, once. And it take less than a millisecond to compile.
We have been using this since Elysia 0.3 and we have not encounter any critical problem.
We also published an academic paper to ACM (Association for Computing Machinery) about this topic, and it is well received.
But why
The framework is a foundation of your application.
If the foundation is slow, the whole application is going to be slow regardless of your code.
Elysia is designed from the very first to be fast.
We do not want to compromise performance for convenience.
It is a hard problem but I think we are getting somewhere.